How AI Is Changing Data Format Conversion in 2026

Preeti
If you have spent any serious time in data engineering, you already know the frustration. You get a new data source handed to you, and within minutes you are staring at a deeply nested XML file, a half-documented JSON feed, or a CSV that someone in finance built from an export they no longer remember. Converting that into something queryable in your database used to mean hours of scripting, schema detective work, and the quiet dread of edge cases you would not find until production.
That situation has not disappeared in 2026, but AI has changed the economics of it significantly. The steps that used to eat a full day now take minutes in many cases. And more importantly, the kinds of errors that used to slip through unnoticed are increasingly being caught before they cause downstream problems.
Here is a look at what has actually changed, where the real gains are coming from, and what to look for if you are evaluating tools in this space.
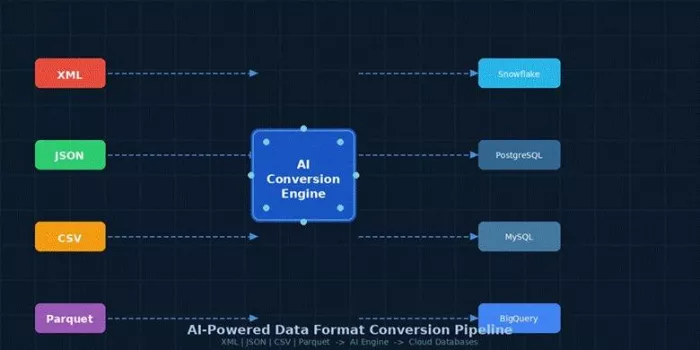
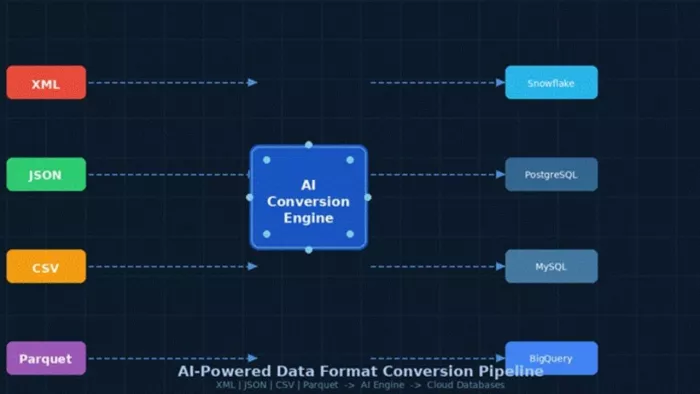
| Figure 1: How AI converts multiple input formats into queryable cloud databases automatically |
Why Data Format Conversion Is Still a Bottleneck
Most enterprise data stacks are not clean. They carry years of accumulated decisions, system migrations, and vendor integrations. A team might be pulling data from an XML-based ERP system, a REST API returning JSON, flat CSV exports from a third-party vendor, and Parquet files sitting in a cloud storage bucket, all feeding into the same analytics layer.
Managing the conversion between all of those is not a one-time task. Schemas change. New fields get added without notice. A supplier updates their XML structure and suddenly a pipeline that ran cleanly for two years starts throwing errors. Fixing it manually means hunting down the schema diff, rewriting the mapping, testing edge cases, and redeploying. That cycle repeats across every data source in the stack.
The volume of this work is what makes it a genuine bottleneck. As AI tools built to make sense of complex engineering data have shown, the sheer amount of structured data flowing through engineering organisations is already outpacing what teams can reasonably handle manually. Data format conversion is one of the biggest places where that overhead builds up quietly.
How AI Is Transforming the Conversion Process
The changes happening in this space are not about one single breakthrough. They are a collection of capabilities that, taken together, make the whole conversion workflow significantly less painful.
Automatic Schema Detection and Mapping
Legacy ETL tools required you to define the mapping upfront. You told the tool what fields existed, what their types were, and how they related to each other. If you were lucky, you had a schema file. If you were not, you were building that mapping by hand from sample data.
AI-based tools now infer schema from the data itself. They analyse the structure of an incoming file, whether it is a flat CSV or a deeply nested XML document, and generate a working schema without manual definition. Schema mismatches, which used to be one of the most common causes of pipeline failures, are caught before the conversion runs rather than discovered after it breaks.
Intelligent Normalisation of Hierarchical Data
This is the one that makes the biggest practical difference for XML and JSON workflows. Hierarchical data does not map cleanly to relational tables without someone deciding how to handle parent-child relationships, repeated elements, and nested arrays. Doing that well has historically required a developer who understood both the source format and the target schema.
AI identifies those relationships automatically and generates a relational table structure that reflects the actual hierarchy of the source data. Sonra's XML to SQL converter automates exactly this step, turning nested XML into queryable relational tables without manual coding, and outputting a source-to-target mapping file so you have full data lineage from day one.
Error Handling and Edge Case Resolution
Traditional conversion scripts fail in predictable ways. They crash on null values, choke on unexpected encodings, or silently drop records that do not match the expected structure. You often do not find out until a downstream report shows a number that does not add up.
AI-assisted conversion adds a layer of anomaly detection to this process. When a field is missing, when a value falls outside an expected range, or when an encoding issue appears in part of a file, the tool flags it rather than ignoring it or crashing. You end up with a conversion that is both more complete and more auditable.
Natural Language Interfaces Are Lowering the Barrier
This one is worth paying attention to even if you are a technical user. The shift toward natural language interfaces for data work means that the people triggering conversions no longer need to understand the underlying mechanics. A data analyst who knows what output they want can describe the transformation they need and have it executed without writing a single line of code.
For teams where conversion requests have always been routed to an engineer, this creates real capacity headroom. The engineer is no longer the bottleneck for every format change.
Real-World Impact: Where Teams Are Seeing Results
The industries feeling this most clearly are the ones that have been dealing with format complexity the longest.
In financial services, XML has been the dominant format for transaction data for decades. Moving that data into modern cloud databases for analytics has traditionally required substantial custom engineering. AI-driven conversion cuts that work down significantly, especially when source schemas vary across counterparties and regions.
Healthcare data faces similar challenges. HL7 and CCD formats used in clinical systems are XML-based and notoriously complex. Converting them into queryable SQL schemas for population health analytics or claims processing is exactly the kind of hierarchical normalisation problem that AI handles well.
E-commerce is another area where the volume and variability of supplier data makes this a recurring pain point. Product catalogues arrive in dozens of different XML and CSV structures, and keeping them normalised in a central database is a constant maintenance burden. The pattern is the same one documented in how AI-driven document automation is already reducing processing time in regulated industries: AI removes the manual translation layer between raw data and usable output, regardless of the source format.
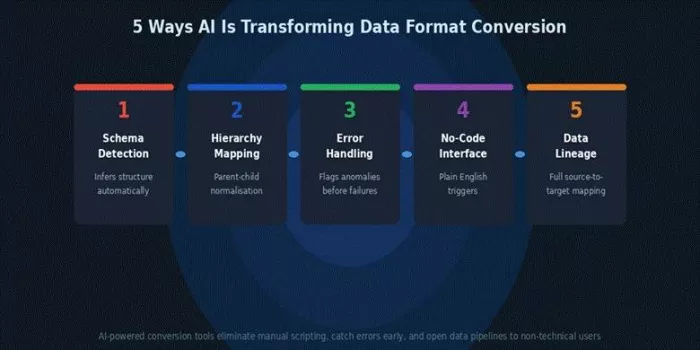
| Figure 2: The five core AI capabilities reshaping how data teams handle format conversion in 2026 |
What to Look for in an AI-Powered Conversion Tool
Not every tool in this space delivers on the same things. If you are evaluating options, these are the criteria that actually matter in production environments.
Schema automation: The tool should infer structure from sample data without requiring you to supply a pre-built XSD or DDL. If it still needs manual field mapping to get started, it is not saving you the hard part.
Output flexibility: Your target database should not be dictated by the tool. Look for support across major platforms, whether that is Snowflake, PostgreSQL, MySQL, or others, rather than a single vendor lock-in.
Data lineage documentation: A conversion that cannot show you where each field came from is a liability in any audited environment. Source-to-target mapping files are not optional in financial services or healthcare contexts.
Scalability: Many tools demo beautifully on a 1 MB sample file and fall over on a 2 GB production dataset. Make sure you are testing with representative file sizes before committing.
No-code accessibility: If running a conversion still requires an engineer to write a script, you have not reduced the bottleneck, you have just shifted it. The best tools let non-technical users run standard conversions independently.
The Takeaway
Data format conversion has always been one of those unglamorous problems that every engineering team deals with but nobody wants to talk about. It sits in the gap between where data comes from and where you need it to be, and it has historically consumed a disproportionate amount of time for the value it delivers.
AI is not making that gap disappear, but it is making it much cheaper to cross. Automatic schema detection, intelligent normalisation of hierarchical structures, smarter error handling, and natural language interfaces are all moving in the same direction: less manual work, fewer silent failures, and more people who can participate in the process without being SQL experts.
If your team is still handling these conversions through custom scripts and manual mapping, it is worth taking a serious look at what the current generation of AI-powered tools can do. The gap between what is possible now and what most teams are actually doing is wider than it has been in a long time.
Comments